
The Hidden Dangers of Open-Source Data: Why It’s Time to Rethink Your AI Training Strategy
26 Feb 2025
There are noises coming from the AI community that in recent years have grown from a murmur to a roar. Is open-source data all it’s cracked up to be?
Using open-source data can make developing AI models more accessible, but it's not always positive—think murky licensing, malware and copyright infringement. While open source’s low costs enable companies to move quickly, we’re seeing many major players cut corners just to be first to market. So, how does a company reconcile being “the first” with being “a leader”? At Defined.ai, we see ethics and legal implications as one and the same. We know firsthand what choosing expedience over responsible AI use means for end users, brand reputation and financial outlook.
Our Head of Marketing, Christine Payne, sat down with the Market Research team—Senior Director of Business Development and Strategic Partnerships, Ian Turner and Senior Strategic Partnerships & Alliances Manager, Sebastião Villax—to understand what’s driving these business decisions and expose the ugly truth of open-source data. As the saying goes, “pay cheap, pay thrice”!
Is all fair in love and open-source AI models?
Christine Payne: With Valentine’s Day just behind us, everybody should know the cheaper, faster solution isn’t always the best. But what risks are AI developers taking by choosing to ignore the difference between open-source versus vendor-procured data? How are you seeing these risks materialize today?
Market Research Team: Open source definitely works in many cases, and generally speaking, has been good for society. But AI innovators need to remember that not all data is created equal.
Whenever you opt for open source, you open yourself up to risks that can affect every element of your business. From training on data without creator consent to using a code repo with unclear licensing—or even downloading a model laced with malware—there are a lot of downsides. Cutting corners can lead to some potentially serious legal, reputational and security headaches.
We’ve seen these risks manifest throughout the industry. For example, a recent audit revealed that over 75% of GitHub’s repositories lack clear licensing—that’s 609 million data assets, enough to train almost three ChatGPT-3’s! Then there’s dataset controversies like “the Pile” and LAION’s 5B images, which allegedly used copyrighted works without consent and sparked legal pile-ons. Even Hugging Face, a leader in open-source AI, has faced scrutiny for “embracing” potentially thousands of malicious models.
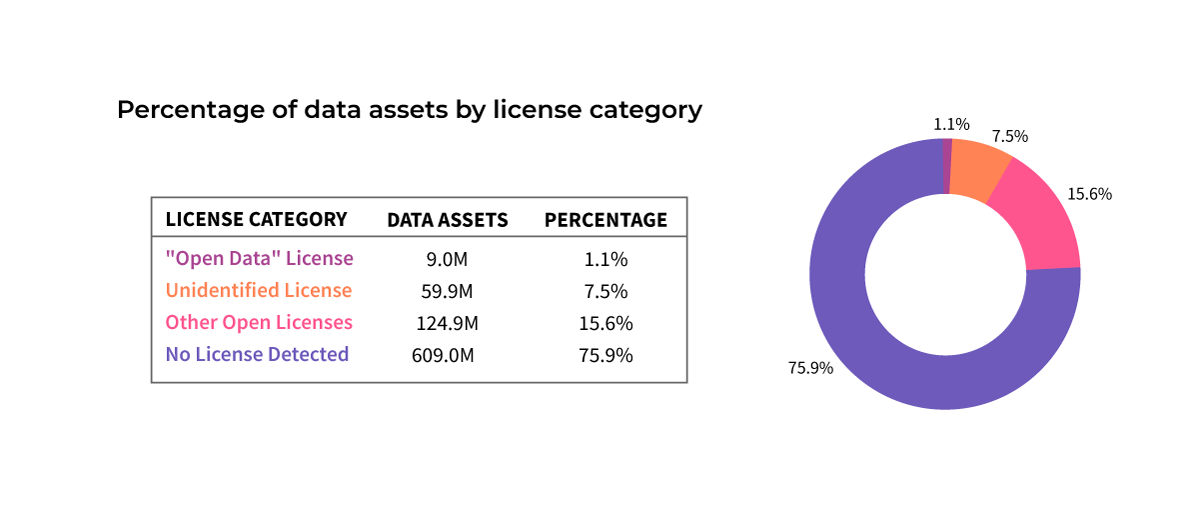
Source: Open Data on GitHub: Unlocking the Potential of AI, Anthony Cintron Roman and others. arXiv:2306.06191v1 [cs.LG], 9 Jun 2023.
Web scraping the barrel for content
[CP]: Many of these risks seem, well, obvious, but let’s unpack them a bit more. How do issues like compliance, quality or transparency in open-source datasets impact the performance of AI solutions?
[MR Team]: I think it comes down to finding a balance between what’s right versus what’s expedient and affordable, though the quicker, cheaper path can often lead to problems later. By adopting an “open-source first” policy for every data need, due diligence can be outnumbered and outgunned in a wild west full of cowboy data curators. This is not to say these curators are all nefarious data rustlers, it’s just that they may not have the same legal considerations that companies do. Take a simple example: the Common Crawl dataset. It’s curated and maintained by a non-profit using web-scraped content, but its creators offer no guarantees against the risks of using the data. Apart from compliance and reputation issues, there’s also a real risk of model performance degradation, too. Hugging Face and others are openly discussing crawling the web and using LLMs to generate synthetic datasets to boost supplies of new text. Web scraping itself is questionable but using this data to generate more open-source content is another level, with some experts saying it leads to “model collapse”. This is as bad as it sounds, with models performing worse after training, not better.
Cheap data, cheap stereotypes
To build AI models that perform well in [fairness], companies need to go beyond open source and invest in curated, representative datasets.
[CP]: When we talk about fairness, it’s not just a cheap stereotype to say that companies are exposing themselves to challenges when opting for open-source AI training datasets. So, what should they be aware of along the lines of diversity or bias?
[MR Team]: AI models trained on open-source datasets often struggle with fairness, diversity and bias, as shown in benchmarking studies. Models like GPT-4 Turbo, Claude 3 Opus, and Mixtral-8x7B sometimes generate outputs that reinforce stereotypes and lack demographic representation.
The issue isn’t just the datasets themselves: bias stems from how the model is trained and how different datasets are leveraged. Since most open-source datasets aren’t curated for fairness, like Common Crawl or Wikipedia, models trained on them tend to inherit and amplify societal biases.
To build AI models that perform well in these areas, companies need to go beyond open source and invest in curated, representative datasets. Broadly available data by itself will not meet fairness standards or regulatory expectations. Instead, businesses should incorporate specialized datasets from providers like us at Defined.ai, which focus on niche demographic representation and ethical sourcing. After that, evaluating output for accuracy and making it attractive to use are important steps toward a great AI model.
AI datasets: think twice, pick once
[CP]: Let’s face it: some companies will continue to use open-source data. What advice can we give these businesses to protect themselves from inadvertently incorporating questionable data into their AI models?
[MR Team]: For the most part, open source is a noble endeavor by the creator community to foster collaboration and innovation. That said, in the AI world, good intentions don't guarantee good outcomes. As you discussed with Melissa [Defined.ai’s in-house legal counsel], many famous authors sued Anthropic for training on the Pile, which included their books. If we assume that their material added up to one million tokens, this would still be less than 0.0002% of the entire set! But you only need a tiny percentage of unethically-sourced data to consider an entire set risky.
To me, the lesson is clear: always measure twice and cut once when it comes to picking datasets for your models. With the Pile, it wasn’t the open-source curators that were sued but Anthropic, so think about accountability and ownership when you’re looking for data partners. At Defined.ai, we stand by our datasets and take (legal) responsibility for verifying the content at every level of the data supply chain.
Less open source, more secret sauce
[CP]: From a competitive standpoint, how does reliance on open-source data impact a company’s ability to differentiate its AI models and maintain a competitive edge?
[MR Team]: It’s certainly harder to stand out. The AI revolution is a classic case of “innovate and imitate” among the frontier research labs and tech giants. Any open-source model, library or dataset that you use your competitors can, too, so you can easily lose the upper hand. Take DeepSeek, for example. The Chinese startup recently shocked the world with its LLM’s remarkably low training cost and high throughput efficiency. However, a closer look shows much of DeepSeek’s “unique” approach is simply combinations of existing methodologies; after a lot of hype, experts are now saying that the major players will soon catch up. Models trained on open-source datasets aren’t much different.
To have an edge on the competition, it’s always best to have some “secret sauce”. We’ve interviewed all sorts of AI companies, from healthcare to gaming, and we found that they always prefer internal data. This makes sense as it gives AI teams access to a unique dataset that’s usually off limits to their competitors, but it’s impossible to have enough of it. Going back to DeepSeek, this is why Open AI is so upset about data theft allegations.
So, when it comes to sourcing, we know that internal data is the gold standard but the same problem persists—there’s never enough. For smaller companies that have even less of it, building their own datasets is too expensive. Instead of relying on just the "free" options, our job is to help them see what ethically-sourced data can do for their models. Again, pay cheap, pay thrice.
Never break the chain (of data custody)
[CP]: With increasing regulations for AI and data privacy, how can businesses make sure the open-source datasets they use align with evolving global standards like GDPR, CCPA and the EU AI Act?
[MR Team]: For anyone who builds AI models, using open-source data isn’t just tricky—it’s a legal and ethical minefield. Getting huge amounts of data is the easy part. The problems start because businesses often have no idea where it comes from, if it’s licensed properly or if it has copyrighted or personal information. There’s no guarantee it will comply with regulations, today or tomorrow.
Open-source datasets are meant to include specific terms, such as MIT, Apache or Creative Commons licenses, to ensure they can be used commercially and comply with privacy laws. However, most of the time this isn’t the case. Unlike curated datasets, open-source data doesn’t come with “chain-of-custody" documentation. So, if there’s an audit or regulatory check it’s impossible to prove transparency, ethical sourcing or legal compliance. As AI regulations tighten, businesses will have to prove the origins of their training data—something you simply can’t do with open-source datasets. Even as US policies head toward deregulation, the Brussels Effect ensures that EU rules will influence global AI governance. This means companies that want to operate internationally will need to comply with strict European AI laws, wherever they’re based.
The safest approach? Partnering with trusted data providers to eliminate the unknowns that come with open-source data.
Don’t wash your hands of data responsibility
[CP]: What are the risks of model contamination when training on open-source data, and how can it affect a business’s ability to commercialize its AI solutions?
[MR Team]: Once a model ingests a dataset, it's essentially impossible to "untrain" something specific. AI can be compared to a computer brain, but we don’t have surgeons that can go in there and look at a particular spot. Unlike a spreadsheet or a database where individual rows can be deleted, knowledge in deep learning models is connected in millions or billions of places at the same time.
The only guaranteed way to remove even a tiny bit of unethically-sourced content from a model is to go back to a previous version. I think the impacts on a company’s products relying on that model speak for themselves. That is, unless you want to pay some hefty lawyer’s fees!
Defining the future of data diversification
I see a shift away from 'open-source-by-default' toward 'curated-data-by-choice': reliable sources led by reputable providers willing to take ownership of exactly where data comes from.
[CP]: Looking ahead, how do you see the landscape of AI model training evolving in terms of data sourcing strategies? What steps should businesses take today to protect their AI investments and brand reputation?
[MR Team]: I see a shift away from “open-source-by-default” toward “curated-data-by-choice”: reliable sources led by reputable providers willing to take ownership of exactly where data comes from. People have been talking about open source’s drawbacks for years now, but in 2025 we’re seeing them act on it. More companies are looking for ethically-verified data sources than ever before.
Through our third-party datasets, we help companies monetize their data securely and responsibly so it can be used to train AI models. Since the backlash against companies like OpenAI and Anthropic, our partner program has become a central aspect of our business. Reputation is more important than ever, and Defined.ai has worked hard to position itself as a trusted AI marketplace leader. Our partnerships with internationally recognized brands like Getty Images show our approach is paying off!
As for open source? Well, whether it’s datasets with questionable origins or models with opaque weights, the means may not always justify the ends in today’s AI world. Much like a savvy investor, forward thinking companies need to diversify their data portfolios to get the best returns.