Data and Model Evaluation
Data and model evaluation for improved AI model performance
Identify errors, reduce bias and improve accuracy with human-in-the-loop data and model evaluation, quality controls and structured testing.
1.6M+
500+
175+
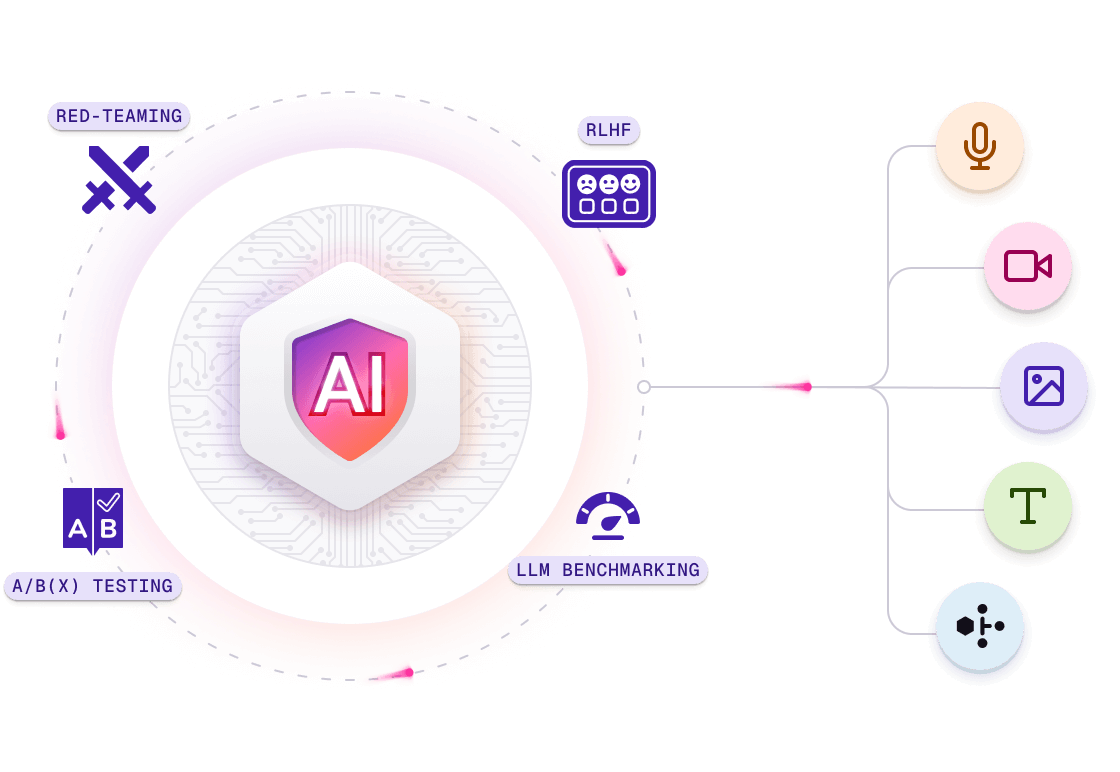
Data and Model Evaluation at Scale
Objective and human-in-the-loop evaluation frameworks designed to measure model performance, ensure data quality, detect bias, and benchmark AI systems with confidence.
Actionable, trustworthy evaluations
Objective and subjective scoring frameworks for data quality assessment, model accuracy, and domain-specific KPIs.
Human‑in‑the‑loop rigor at scale
Global experts and crowd workflows supporting data validation, human evaluation, and reliable precision, recall, MOS, and preference ratings.
Safety first
Adversarial testing exposes bias, toxicity, jailbreaks, and unsafe outputs before launch.
Benchmarking that keeps pace
Assess, build, and continuously update benchmarks for model performance evaluation, robustness, and monitoring.
Production‑grade A/B(x) testing
Compare models, versions, and prompts with statistical significance and stakeholder‑ready dashboards.
RAG, RLHF & DPO expertise
Evaluate grounded retrieval answers and optimize outputs to match user preferences and brand voice.
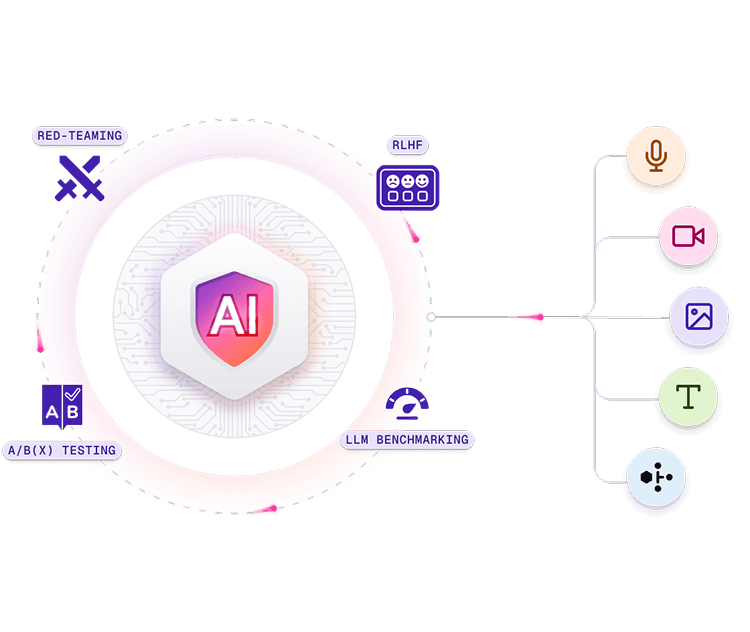
High-Quality Data and Model Evaluation for Any Modality
Access high-quality data and rigorous model validation across audio, image, video, text, and multimodal datasets, ensuring diversity, compliance, and scalability for enterprise AI.
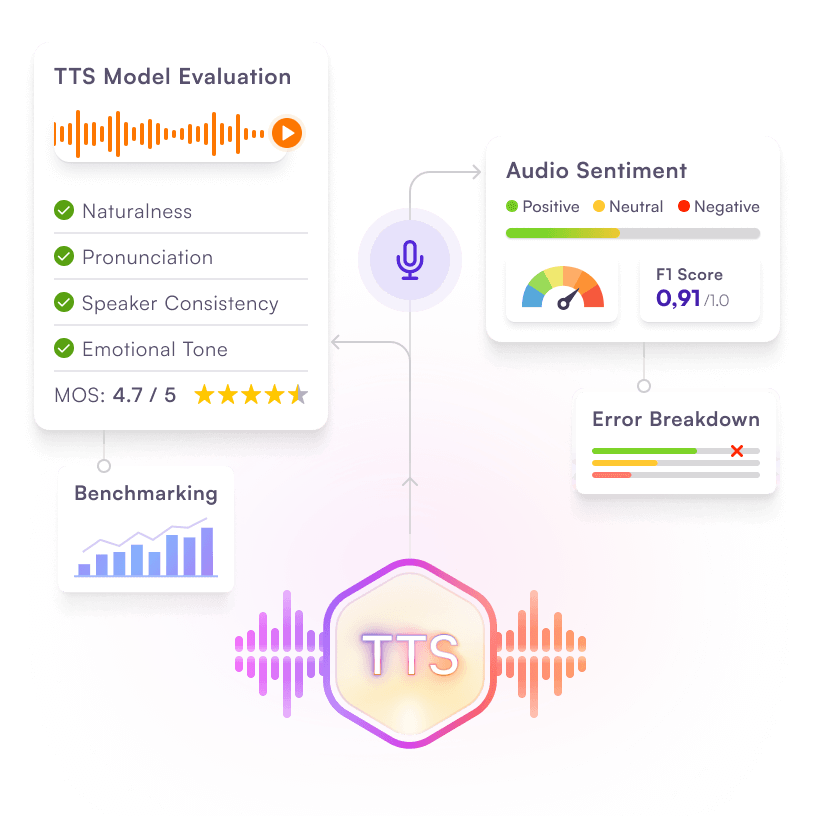
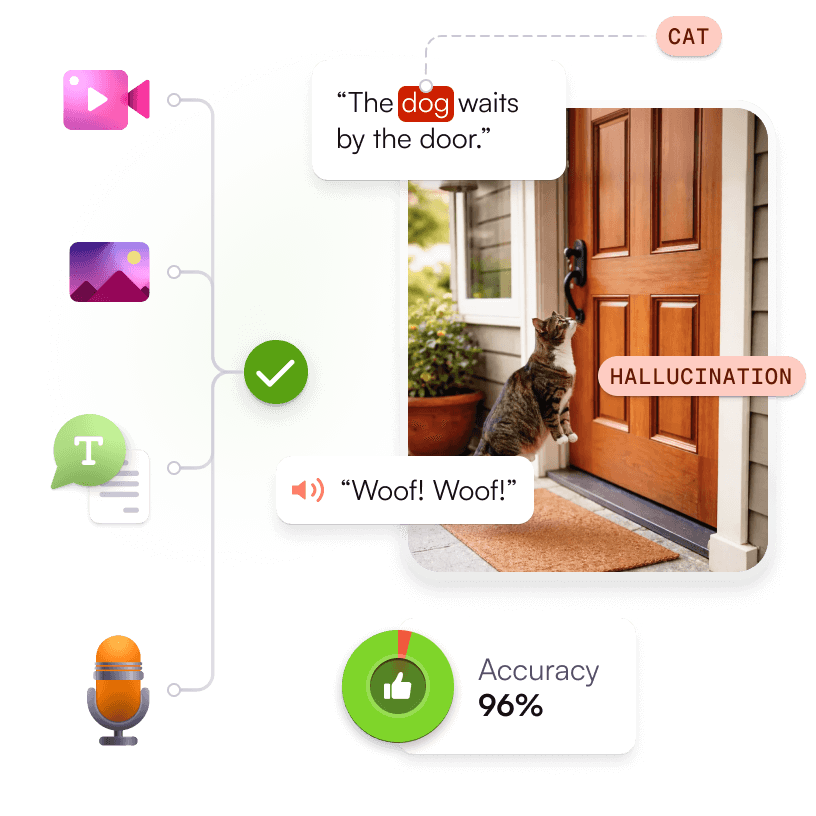
Audio Evaluation
Evaluate and optimize audio models for natural, accurate speech and sentiment:
TTS Model Evaluation: Rate naturalness, MOS scoring, pronunciation accuracy, emotional tone, and speaker consistency; benchmark against industry standards.
Audio Sentiment Analysis: Validate sentiment classification with F1 scoring, error breakdowns, and compliance-aligned dashboards.


Trusted by Leading AI Innovators
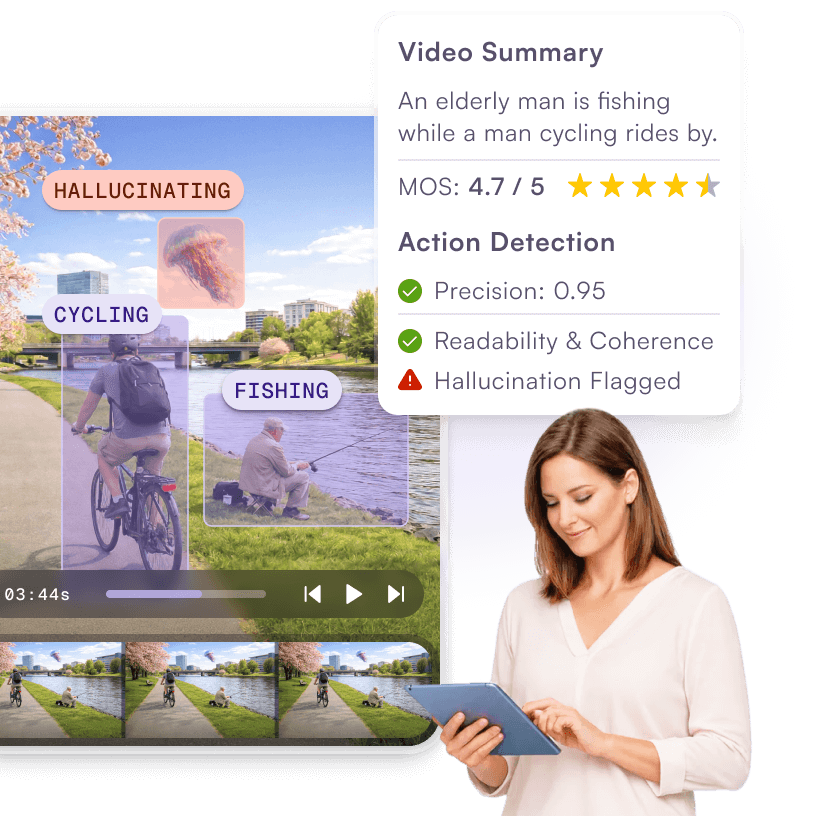
Where rigorous evaluation meets real-world AI challenges
From conversational assistants and global TTS voices to vision-based summarization and grounded LLMs, we tailor evaluations to your data, markets, and risk profile. See more use cases


Train and evaluate ASR models with diverse, high-quality multilingual audio datasets.


Build safer platforms with expertly annotated data for text, image, and video moderation.


Power transcription, summarization, and insights with real-world meeting data.
Proven Trust. Real Impact.
Real feedback from AI teams and enterprises using Defined.ai to power accurate, reliable, and scalable models.


Improving both accuracy and efficiency in AI systems was critical for us. With the introduction of human-in-the-loop evaluation, factual accuracy scores increased by 25%, while the time required for expert corrections dropped by 15% per output—translating into significant annual savings. Our users consistently rate the AI responses highly, with a 9.5-out-of-10 average satisfaction score, often citing factual accuracy and reliability as key strengths.
Learn More About Data and Model Evaluation
Dive deeper into related blogs, success stories and helpful guides.


What Is a Data Marketplace? How It Works and Why It Matters for AI Development
An approachable explainer on data marketplaces, their role in AI ecosystems, and how teams access and monetize quality datasets.

Natural Language Processing in Action: Real-World Examples Across Industries and Applications
Discover how NLP powers search, chatbots, sentiment analysis, translation, automation, and more in practical use cases.


Enhancing Financial Workflows with ASR: Real-World AI Speech Recognition in the Finance Sector
A case study showing how automatic speech recognition drives efficiency, accuracy, and insights in financial operations.
What Is a Data Marketplace? How It Works and Why It Matters for AI Development
An approachable explainer on data marketplaces, their role in AI ecosystems, and how teams access and monetize quality datasets.
Natural Language Processing in Action: Real-World Examples Across Industries and Applications
Discover how NLP powers search, chatbots, sentiment analysis, translation, automation, and more in practical use cases.
Enhancing Financial Workflows with ASR: Real-World AI Speech Recognition in the Finance Sector
A case study showing how automatic speech recognition drives efficiency, accuracy, and insights in financial operations.


FAQ About Our Data and Model Evaluation Solutions
Get clear answers on how our Data and Model Evaluation solutions ensure more accurate, reliable, and high‑performing AI models. Explore the full FAQ
We cover audio (including TTS), image, video, text (LLMs), and multimodal systems—with objective metrics and human-centered subjective ratings tailored to each modality.
We combine modality-specific metrics—e.g., MOS and WER for TTS; precision/recall/IoU for vision; summary correctness and coherence for video; precision/recall/F1 and benchmark performance for LLMs—with preference testing via A/B(x) and RLHF/DPO.
Yes. Our red teaming simulates adversarial scenarios (jailbreaks, prompt injection, unsafe or biased outputs) and produces mitigation steps aligned to enterprise safety protocols and regulatory expectations.
Absolutely. We assess current benchmarks for coverage and gaps, create custom benchmarks with locale/domain specialists, and maintain them with ongoing updates so your evaluations stay relevant over time.
We design controlled experiments, instrument KPIs (accuracy, latency, satisfaction), run significance testing, and integrate continuous comparison workflows—providing dashboards for clear stakeholder visibility.