Data Collection
Custom data collection for high-quality AI training datasets
Diverse, compliant data collection across languages, modalities and geographies—designed to improve data quality and support real-world model performance.
1.6M+
500+
175+
AI Data Collection Services Built for Scale
Enterprise-grade data collection services combining global diversity, automated systems, and certified compliance standards.
Precision Data Gathering
We don’t just collect data—we curate authentic, domain-specific datasets with strict quality and compliance standards.
Global Diversity at Scale
Access contributors in 150+ countries speaking 500+ languages, ensuring cultural and linguistic coverage for unbiased AI.
Ethical & Privacy-First
Every dataset is fully consented, copyright-cleared, and privacy-compliant, meeting GDPR and HIPAA requirements.
Enterprise Scalability
From niche datasets to millions of samples—delivered quickly and competitively.
Certified & Compliant
ISO-certified processes with GDPR and HIPAA compliance for sensitive data handling.
Transparent Quality Assurance
Multi-layer validation and real-time dashboards ensure precision and accountability.
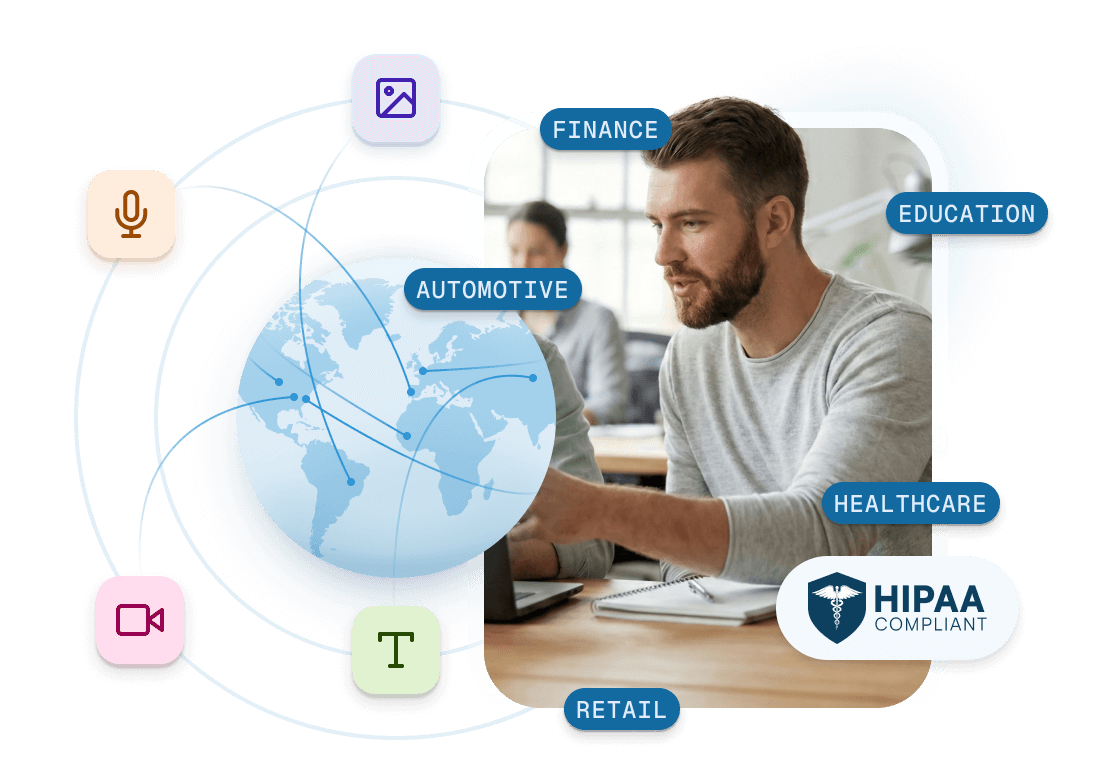
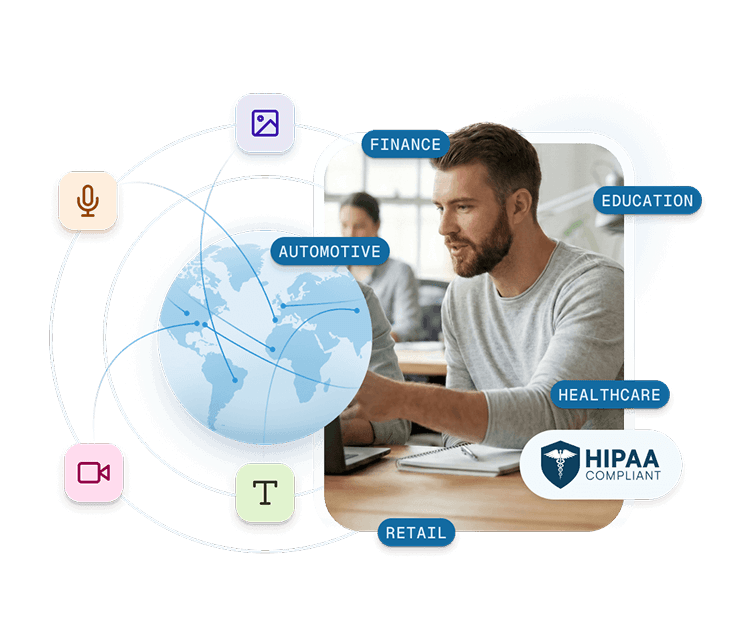
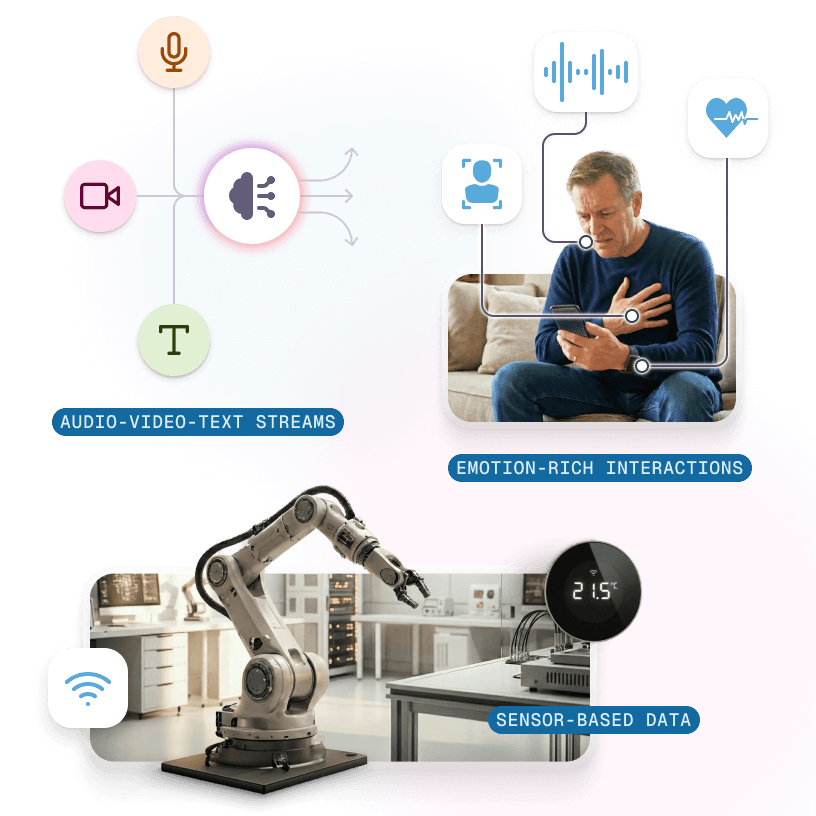
Data Collection Across All Modalities
We offer high-quality data collection across every modality—audio, image, video, text, and multimodal—ensuring diversity, compliance, and scalability for your AI training needs.
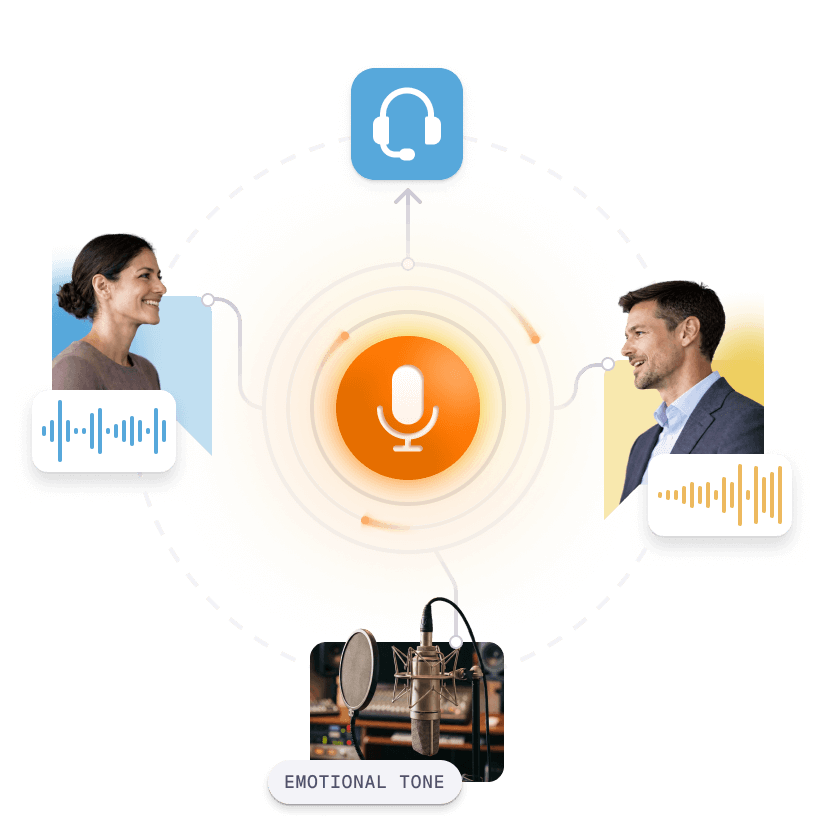
Audio Data Collection
Capture authentic speech data for conversational AI and voice-driven systems:
Conversational Dialogues: Real-world conversations for natural language understanding.
IVR Interactions: Domain-specific voice prompts for call center and automated systems.
Studio Quality Emotional Tone Recordings: Speech samples with varied emotions for empathetic AI responses.



Trusted by Leading AI Innovators
Deliver Smarter AI with Trusted Global Data Collection
Achieve faster deployment and higher model performance with secure, ISO-certified datasets. See more use cases


Access a vetted global crowd to collect, annotate, and evaluate high-quality AI training data at scale.


Trustworthy and Reliable Approach to Enhancing ASR Models to Improve Medical Dictation


Secure and Compliant Data Annotation for Fraud Detection and Risk Management
Proven Trust. Real Impact.
Real feedback from AI teams and enterprises using Defined.ai to power accurate, reliable, and scalable models.


We required large-scale, multilingual data collection to power our AI models, with no room for error. The team delivered over 15,000 validated responses across 17 languages, maintaining a 100% acceptance rate with zero rejections. They sourced more than 850 native speakers from 17 countries—including niche markets—to ensure diverse and representative datasets. Everything was completed ahead of schedule, giving our teams a strong foundation for global AI development.
Learn More About Data Collection
Explore relevant resources and success stories from our customers.


Improving ASR Accuracy: A Case Study in Custom Speech Recognition Model Training and Evaluation
Insights into tailored data pipelines, annotation practices, and evaluation strategies that boosted automatic speech recognition performance.


How Defined.ai Delivered High-Quality French Speech Training Data in Record Time for Rapid Model Development
A case study on accelerating multilingual speech data collection with speed, quality control, and expert crowd workflows.


The Hidden Risks of Open Source Data: What AI Teams Must Know Before Training Models
Explore key dangers of using open source datasets in AI — from licensing pitfalls to bias and quality challenges.
Improving ASR Accuracy: A Case Study in Custom Speech Recognition Model Training and Evaluation
Insights into tailored data pipelines, annotation practices, and evaluation strategies that boosted automatic speech recognition performance.
How Defined.ai Delivered High-Quality French Speech Training Data in Record Time for Rapid Model Development
A case study on accelerating multilingual speech data collection with speed, quality control, and expert crowd workflows.
The Hidden Risks of Open Source Data: What AI Teams Must Know Before Training Models
Explore key dangers of using open source datasets in AI — from licensing pitfalls to bias and quality challenges.


FAQ About our Data Collection Services
Get clear answers on how our data collection solutions help drive better decisions. Explore the full FAQ
We collect speech, image, video, text, and multimodal datasets, including specialized formats like egocentric POV videos, gesture datasets, emotional tone recordings, and sensor-based data for robotics and IoT.
Our process includes rigorous contributor screening, multi-layer validation (automated checks + human review), and real-time monitoring dashboards to guarantee accuracy, diversity, and compliance.
Yes. All projects follow ISO-certified workflows and are fully GDPR and HIPAA compliant, ensuring privacy, security, and regulatory adherence for sensitive data.
Absolutely. We deliver millions of samples at scale through our vetted global crowd of 1.6M+ contributors across 150+ countries and 500+ languages, supported by secure API integrations and enterprise-grade reporting.
We source contributors from diverse regions, languages, and cultures, and apply bias detection and fairness checks throughout the collection process to ensure representative and unbiased datasets.